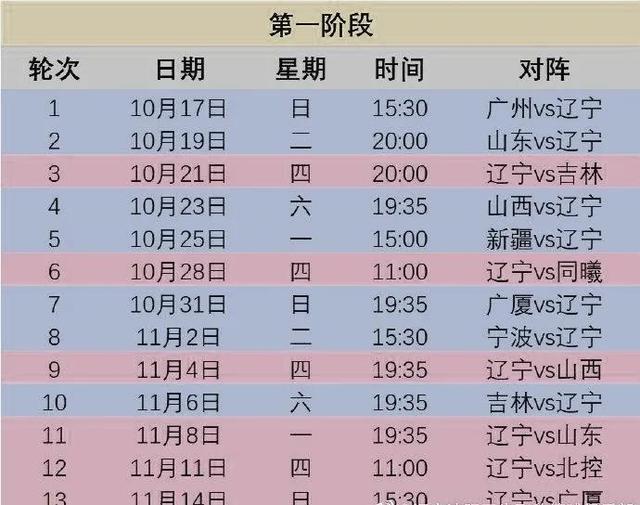
2023男篮世预赛赛程时间表与日本中国台北同在B组
一、hadoop 概述1、为什么选择大数据
随着信息技术的发展,各行各业产生的数据越来越多,数据量也越来越大。传统的数据处理模式已经不能满足大数据的增长。
1)存储问题
数据库存储:假设每个人访问简书,每天浏览5篇文章。如果1亿人浏览,简书会在后台生成约5亿条记录。如果将这些记录存储在数据库中,存储这些数据的数据库服务器的性能会非常高,往往这样的服务器的价格要比普通服务器贵很多倍。
据此,每天添加一个高性能服务器来存储新数据并不能解决根本问题。
大数据存储:可以在低成本硬件上使用,服务器不需要高性能,数据会存储在磁盘上,可以备份。如果磁盘空间已满,请增加磁盘并重新存储。
2)分析数据问题
大数据分析:分布式计算、实时处理技术。
磁盘计算:计算过程中,多次登陆磁盘,离线计算,mapreduce。
内存计算:在内存中计算,类似于实时处理技术,spark。
2、什么是hadoop
Hadoop 是 Apache 的顶级项目。 Apache:APACHE 软件基金会,支持 Apache 的开源软件社区项目,向大众提供优秀的软件产品。
Apache 项目主页:
Hadoop 项目是为可靠、可扩展和分布式计算而开发的开源软件。
可靠:存储可靠,数据有备份。优点:如果磁盘或机器坏了,数据不会丢失,可以从备份机器上取数据。
可以横向扩展:扩展存储空间、扩展磁盘、扩展机器磁盘;扩展计算节点,增加机器,扩展计算内存。
3、大数据(4V)的主要特点
首先,数据容量大(Volume)。从TB级到PB级。
第二,数据的种类很多(Variety)。与以往易于存储的基于文本的结构化数据相比,非结构化数据越来越多,包括网络日志、音频、视频、图片、地理位置信息等。
第三,高商业价值(Value)。细分客户群,提供定制化服务;在提高投资回报的同时发现新的需求;降低服务成本。
第四,处理速度(Velocity)。这是区分大数据与传统数据挖掘的最显着特征。根据IDC《数字宇宙》报告,预计到2020年全球数据使用量将达到35.2ZB。面对如此海量的数据,处理数据的效率是企业的生命。
4、hadoop 的历史
创始人:Doug Cutting 和 Mike Cafarella
自 2002 年以来,两位创始人开发了一个开源搜索引擎解决方案:Nutch
受 Google Lab 于 2004 年开发的 Map/Reduce 和 Google File System (GFS) 的启发,Nutch 引入了 NDFS(Nutch 分布式文件系统)
Doug Cutting,曾在 Yahoo! 工作2006年,将这款大数据处理软件命名为Hadoop
5、hadoop 核心组件
hadoop主要用于解决两个核心问题:存储和计算。
1)Hadoop Common:一组用于分布式文件系统和通用 I/O(序列化、Java RPC 和持久数据结构)的组件和接口。
2)Hadoop分布式文件系统(Hadoop分布式文件系统HDFS)
3)Hadoop MapReduce(分布式计算框架)
4)Hadoop YARN(分布式资源管理器)
6、hadoop的框架演进
Hadoop1.0的MapReduce(MR1):集资源管理、任务调用、计算功能于一体,扩展性差,不支持多种计算框架。
Hadoop2.0 Yarn (MRv2):分离资源管理和任务调用大数据分析,提高可扩展性,支持多种计算框架。
7、hadoop 生态系统
1)HDFS(Hadoop 分布式文件系统)
HDFS 是一种分布式的数据存储机制,数据存储在计算机集群上。数据一次写入大数据分析,多次读取。 HDFS 为 HBase 等工具提供了基础。
2)Hadoop YARN(分布式资源管理器)
YARN 是 MapReduce 的下一代,即 MRv2,它是从第一代 MapReduce 演变而来的。主要是为了解决原有Hadoop扩展性差,不支持多种计算框架的问题而提出的。
核心思想是将MR1中JobTracker的资源管理和作业调用功能分离,分别由ResourceManager和ApplicationMaster进程实现。
1)ResourceManager:负责整个集群的资源管理和调度
2)ApplicationMaster:负责应用相关的事务,如任务调度、任务监控和容错等。
3)MapReduce(分布式计算框架)
MapReduce 是一种分布式计算模型,用于计算大量数据,是一个离线计算框架。
简而言之,这个 MapReduce 的计算过程就是将一个大数据集分解成几个小数据集,每个(或几个)数据集由集群中的一个节点(通常是主机)组成。 ) 处理并生成中间结果,然后将各个节点的中间结果组合起来形成最终结果。
4)Spark(内存计算模型)
Spark 提供了一个更快、更通用的数据处理平台。与 Hadoop 相比,Spark 可以让您的程序在内存中运行时快 100 倍,或者在磁盘上运行时快 10 倍。
5)Storm(流计算、实时计算)
Storm 是一个免费、开源、分布式和容错的实时计算系统。 Storm 让连续流计算变得简单,弥补了 Hadoop 批处理无法满足的实时性要求。 Storm 常用于实时分析、在线机器学习、连续计算、分布式远程调用和 ETL。
6)HBASE(分布式列存储数据库)
HBase 是基于 HDFS 构建的面向列的 NoSQL 数据库,用于快速读取/写入大量数据。 HBase 使用 Zookeeper 进行管理,以确保所有组件都正常运行。
7)Hive(数据仓库)
Hive 定义了一种类似 SQL 的查询语言 (HQL),可将 SQL 转换为 MapReduce 任务以在 Hadoop 上执行。通常用于离线分析。 HQL 用于运行存储在 Hadoop 上的查询语句,而 Hive 使不熟悉 MapReduce 的开发人员可以编写数据查询语句,然后将其转换为 Hadoop 上的 MapReduce 任务。
8)Zookeeper(分布式协作服务)
Hadoop 的许多组件都依赖于 Zookeeper,它在计算机集群上运行以管理 Hadoop 操作。
作用:解决分布式环境下的数据管理问题:统一命名、状态同步、集群管理、配置同步等
9)Sqoop(数据ETL/同步工具)
Sqoop 是 SQL-to-Hadoop 的缩写,主要用于传统数据库和 Hadoop 之间的数据传输。
10)flume(分布式日志采集系统)
Flume 是一个分布式、可靠且高度可用的海量日志聚合系统。例如,从各种网站服务器收集日志数据,并存储在 HDFS 和 HBase 等中心化存储中。
11)猪(临时脚本)
Pig 定义了一种数据流语言 Pig Latin,它是 MapReduce 编程复杂性的抽象。 Pig 平台包括一个运行时环境和一种用于分析 Hadoop 数据集的脚本语言(Pig Latin)。它的编译器将 Pig Latin 翻译成 MapReduce 程序序列,并将脚本转换成 MapReduce 任务,以便在 Hadoop 上执行。通常用于离线分析。
12)Oozie(工作流调度器)
Oozi 可以将多个 Map/Reduce 作业组合成一个逻辑工作单元来完成更大的任务。
13)Mahout(数据挖掘算法库)
Mahout 的主要目标是为机器学习领域的经典算法创建一些可扩展的实现,旨在帮助开发人员更轻松、更快速地创建智能应用程序。
14)Tez(DAG计算模型)
支持在 YARN 之上运行的 DAG(有向无环图)作业的计算框架。 Tez 的目的是帮助 Hadoop 处理 MapReduce 无法处理的这些用例场景,例如机器学习。
郑重声明:文章仅代表原作者观点,不代表本站立场;如有侵权、违规,可直接反馈本站,我们将会作修改或删除处理。
相关阅读





猜你喜欢
-
大数据可视化的优势:引入数字这一关键技术
2022-04-03